







Despite the unprecedented success of text-to-image diffusion models, controlling the number of depicted objects using text is surprisingly hard. This is important for various applications from technical documents, to children’s books to illustrating cooking recipes. Generating object-correct counts is fundamentally challenging because the generative model needs to keep a sense of separate identity for every instance of the object, even if several objects look identical or overlap, and then carry out a global computation implicitly during generation. It is still unknown if such representations exist. To address count-correct generation, we first identify features within the diffusion model that can carry the object identity information. We then use them to separate and count instances of objects during the denoising process and detect over-generation and under-generation. We fix the latter by training a model that proposes the right location for missing objects, based on the layout of existing ones, and show how it can be used to guide denoising with correct object count. Our approach, CountGen, does not depend on external source to determine object layout, but rather uses the prior from the diffusion model itself, creating prompt-dependent and seed-dependent layouts. Evaluated on two benchmark datasets, we find that CountGen strongly outperforms the count accuracy of existing baselines.
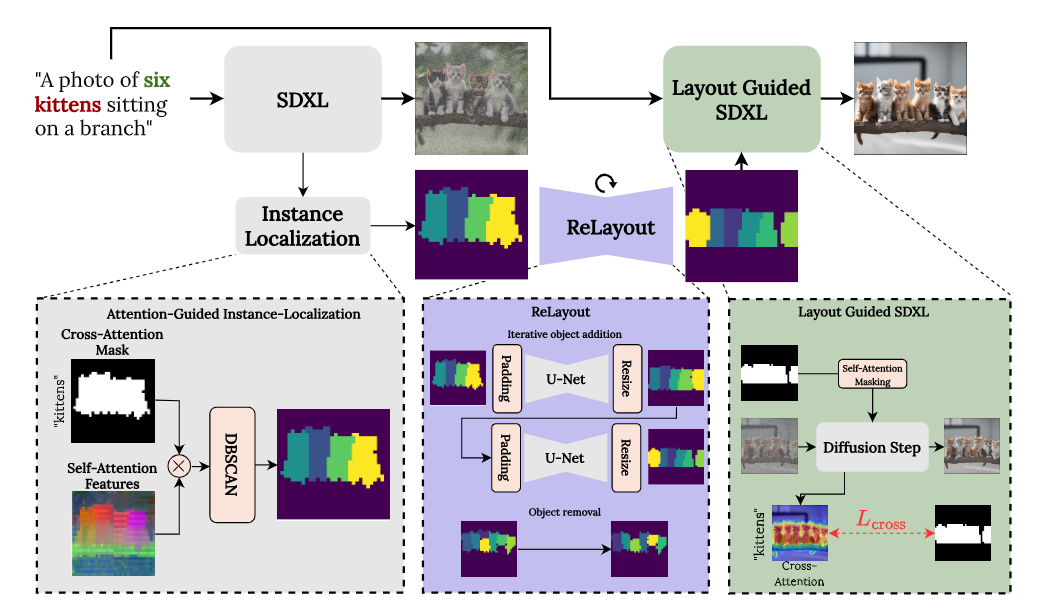
Our method, CountGen, aims to enhance text-conditioned image generators to accurately produce the intended number of objects for complex input prompts. Our methodology involves a two-step process: initially, we generate a natural layout that specifies where and how objects should appear in the image. That layout is based on a layout that emerges naturally from the text-conditioned generation. At the second step, we use this layout as a blueprint to generate the final image.

While most layers do not exhibit separability at the instance level, we notice that a specific layer at a specific timestamp tends to generate different features for different instances of the same object. Based on this finding, we select the self-attention features to serve as our instance-level features.
-1.png)
To address under-generation issues, we train a U-Net model to predict a new layout, represented as a multi-channel mask. To train our ReLayout U-Net, we need a dataset of layout pairs with k and k +1 objects, that maintain the same scene composition. We begin with the empirical observation that slight variations in the object count specified in the prompt—while keeping the starting noise and the rest of the prompt consistent—typically results in images with similar layouts. This consistency is crucial as it allows us to generate a training dataset of layout pairs where each pair has a similar object composition, differing by only one object, thereby preserving the overall scene structure.

We evaluated CountGen against DALLE 3, Reason Out Your Layout, SDXL, Repeated Object SDXL and Counten Layout + Bounded Attention. Our method successfully generates the correct number of objects, while other methods struggle in some or all of the examples.
If you find our work useful, please cite our paper:
@article{binyamin2024count,
title={Make It Count: Text-to-Image Generation with an Accurate Number of Objects},
author={Binyamin, Lital and Tewel, Yoad and Segev, Hilit and Hirsch, Eran and Rassin, Royi and Chechik, Gal},
journal={arXiv preprint arXiv:2406.10210},
year={2024}
}